
이번 게시물에서는 JPA 최적화와 여러 가지 배경 지식을 알아보도록 하겠습니다.
정답은 아니지만 저의 기준과 나름대로 얻었던 인사이트를 공유하고자 합니다.
📌 N+1 문제와 해결법에 대해서 정확하게 알아보자
✅ N+1 문제란?
JPA 성능 최적화를 공부하게 된다면..? 아니 그 이전에 JPA라는 기술을 공부하게 된다면 가장 먼저 마주하는 개념 중 하나입니다. 또한, 성능 최적화에서 고려해야 할 가장 중요하면서도 기본적인 개념입니다.
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
private String name;
@ManyToOne
private Team team;
}@Entity
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
}예를 들어서 다음과 같이 Member와 Team이 존재하는 경우를 생각해 봅시다.
List<Member> members = em.createQuery(
"SELECT m FROM Member m", Member.class
).getResultList();
만약 현재 상태에서 다음과 같이 List<Member>를 가져오는 쿼리를 날리게 되면..?
모든 Member마다 Team이 즉시 로딩( default로 FetchType.Eager 상태)되면서 N+1 문제가 발생하게 됩니다.
// 최초로 나감
SELECT * FROM member;
// 각 Member마다 나감 (N번 발생)
SELECT * FROM team WHERE id = ?;로그를 찍어보면 이렇게 쿼리가 나가는 것을 확인하실 수 있을 거예요.
🔥 그래서 모든 경우에 FetchType.Lazy를 설정해 놓는 것은 당연한 상식입니다.
FetchType.LAZY는 연관 객체를 프록시(Proxy)로 보관해 두고, 해당 객체가 실제로 사용될 때까지 쿼리 실행을 미루는 방식입니다. 프록시는 진짜 객체가 아닌 진짜 객체를 대신하는 대리인으로 이해하면 좋습니다.
실제로 사용하게 된다면 '초기화'가 일어나며 실제 Team을 가져오는 쿼리가 그때 나가게 됩니다.
여기서 실제로 사용하게 된다는 것은 예를 들어서, member.getTeam().getName()과 같이 실제로 member를 DB에서 가져와야 하는 상황을 의미합니다. member.getTeam().getId()같은 경우는 실제 member가 필요 없기 때문에 초기화되지 않습니다. 초기화 조건이 이해가 되시나요?
하지만, FetchType.Lazy를 설정해 두는 것만으로 완벽하게 N+1 문제를 해결할 수는 없습니다.
List<Member> members = em.createQuery(
"SELECT m FROM Member m", Member.class
).getResultList();
for (Member member : members) {
System.out.println(member.getTeam().getName());
}FetchType.Lazy 설정이 되어 있다면 List<Member>를 불러오는 시점에서는 N+1 문제가 발생하지 않습니다 (모든 Team 필드는 프록시 상태). 하지만 결국 for loop을 돌면서 순차적으로 모든 Team 필드가 초기화될 것이고, 이로 인해서 여전히 N+1 문제가 발생하게 됩니다. 그래서 다음과 같은 상황에서는 Batch 처리 , JPQL을 활용한 FetchJoin,그리고 EntityGraph를 이용해서 Join된 그래프를 가져오는 방법으로 해결해 주어야 합니다.
각각을 알아보고 어떤 차이가 있는지 실전적으로 어떻게 활용할 수 있는지 확인을 해보겠습니다.
✅ Batch 처리
Batch처리를 완벽히 N+1 문제를 해결하는 방법은 아닙니다. 어느 정도 '완화'할 수 있는 방법으로 보면 될 것 같아요.
예를 들어서 BatchSize를 5로 설정하고 위의 예시처럼 member마다 .getTeam()으로 초기화하게 된다면 N+1번의 쿼리가 나가는 것이 아니라 (N/5)+1번의 쿼리가 나가게 됩니다. Batch처리는 필드에 어노테이션을 달아주면서 구현할 수도 있고 yml레벨에서 처리할 수도 있습니다.
@Entity
public class Car {
@Id @GeneratedValue
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY)
@BatchSize(size = 10)
private Member member;
}다음과 같이 필드에 명시해줄 수 있고
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 100yml에 설정을 해주며 전역적인 설정이 가능합니다.
사실 Batch 기능은 N+1 문제를 완전히 없애주지는 않기 때문에 N+1 문제만을 두고 본다면 EntityGraph나 JPQL을 통한 Fetch Join더 효과적입니다. 저는 프로젝트에서 양방향 매핑을 사용하지 않기 때문에 MultipleBagFetchExcetion이나 다른 문제들을 마주한 적이 없지만, 양방향 매핑이 포함된 관계를 fetch Join할 경우 앞에서 언급한 exception이 터질 수 있으며 이외에도 Batch를 활용해야 하는 경우가 종종 있습니다. ( EntityGraph와 FetchJoin을 설명한 이후에 알아보죠)
✅ EntityGraph (Spring Data JPA 공식 문서 : 🔗)
Entity Graph는 기본적으로 FetchJoin과 비슷하다고만 우선 알고 계시면 됩니다. 세부적인 코드를 알아보도록 하겠습니다.
Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD, ElementType.ANNOTATION_TYPE})
@Documented
public @interface EntityGraph {
String value() default "";
EntityGraphType type() default EntityGraph.EntityGraphType.FETCH;
String[] attributePaths() default {};
public static enum EntityGraphType {
LOAD("jakarta.persistence.loadgraph"),
FETCH("jakarta.persistence.fetchgraph");
private final String key;
private EntityGraphType(String value) {
this.key = value;
}
public String getKey() {
return this.key;
}
}
}EntityGraph의 코드를 확인해 보겠습니다. 3가지 필드가 존재하고 이 부분들을 살펴보면 되겠습니다.
1️⃣ value (default : "")
정의된 NamedEntityGraph의 이름이고 만약 이 값을 입력하지 않는다면 Spring이 메서드 이름 기반으로 자동 유추합니다.
간단히 설명해서, "미리 지정한 EntityGraph를 사용할 거니?"라고 생각하면 되겠습니다. 그래프 이름을 써주면 그대로 써주면 됩니다. 뒤에서 설명할 attribute 필드를 지정하는 것을 통해서는 미리 지정하지 않고 동적으로 엔티티 그래프를 만들 수 있는데요, attributePaths 필드를 작성하게 되면 value 필드가 무시되게 됩니다. Spring이 메서드 이름 기반으로 자동 유추한다는 것은 attributePaths 필드도 명시하지 않고 value도 작성하지 않는다면 메서드 이름에 따라서 유추해서 찾는다는 뜻입니다.
위의 내용을 이해하기 위한 부연 설명을 해보겠습니다.
Entity Graph란 무엇일까?
Entity Graph란 엔티티를 조회할 때 어떤 연관관계를 함께 즉시 로딩(fetch)할지 지정한 "쿼리 스펙"입니다.
@Entity
@NamedEntityGraph(
name = "Post.withAuthor",
attributeNodes = @NamedAttributeNode("author")
)
public class Post {
@ManyToOne(fetch = FetchType.LAZY)
private Author author;
@OneToMany(mappedBy = "post")
private List<Comment> comments;
}저렇게 엔티티를 선언하면서 미리 지정해 놓을 수 있습니다. 보면 attributeNodes에 "author"를 해놓았는데요, 이는 author 필드만 즉시로딩하고 나머지 필드는 default로는 Lazy Loading 됨(이는 EntityGraphType 필드랑 관련이 있음). 그리고 엔티티 그래프의 이름은 Post.withAuthor로 지정해 놓은 것입니다.
@EntityGraph(value = "Post.withAuthor")
List<Post> findAll();그리고 EntityGraph의 이름을 저렇게 value에 넣어 주게 된다면?
Post.withAuthor에서 지정해 놓은 전략에 따라 author 필드만 미리 로딩을 하게 되는 것이죠.
그리고 참고사항으로 이름 기반의 자동 유추는 사실 크게 중요하지는 않지만
엔티티 클래스명 + "." + 메서드 이름의 NamedEntityGraph를 찾습니다.
public interface PostRepository extends JpaRepository<Post, Long> {
@EntityGraph
List<Post> findByTitle(String title);
}예를 들어서 다음과 같이 findByTitle이라는 이름의 메서드를 작성하고 value값과 attribute 값을 주지 않았기 때문에...
"Post.findByTitle"이런 이름의 NamedEntityGraph를 알아서 찾아보게 되겠네요~
2️⃣ attributePath (default: {})
value 입력 인자는 "미리 만들어 놓은 NamedEntityGraph를 사용하겠다 !"라는 뜻이고 attributePaths 필드는 "지금 알려주는 조건에 따라서 동적으로 EntityGraph를 만들어줘!"라는 뜻입니다. 따라서, attributePaths 필드를 사용하게 되면 value 필드를 언급해도 attributePaths 필드에 따라서 동적 EntityGraph로 처리됩니다.
@EntityGraph(attributePaths = {"author", "comments"})
List<Post> findAll();다음과 같이 만들어 주게 된다면 Post 엔티티의 author과 comments를 즉시 로딩해 오게 됩니다(간단하죠?).
사실, 저도 대부분의 경우에서 굳이 NamedEntityGraph를 만들어 놓을 필요가 있나 싶긴 합니다. 실제 프로젝트에서도 대부분의 상황에서 동적으로 attributePaths를 사용할 것 같아요.
⚠️ 참고 : 만약 트리구조로 연결되어 있는 경우
A->B->C로 직렬 상태로 연결된 경우
@Entity
@NamedEntityGraph(
name = "Post.withCommentsAndLikes",
attributeNodes = @NamedAttributeNode(value = "comments", subgraph = "commentsWithLikes"),
subgraphs = @NamedSubgraph(
name = "commentsWithLikes",
attributeNodes = @NamedAttributeNode("likes")
)
)
public class Post {
@OneToMany(mappedBy = "post", fetch = FetchType.LAZY)
private List<Comment> comments;
}NamedEntityGraph는 subgraph를 이용해야 하며
@EntityGraph(attributePaths = {"comments", "comments.likes"})
List<Post> findAll();attributePaths를 통해서 할 때는 문자로 중첩 구조를 표현해 주면 됩니다.
여러가지 관점에서도 그냥 attributePaths가 편리한 것 같네요..?
매핑 방식(양방향, 단방향)과 중첩 구조( 트리구조 - 직렬 구조, 무작위 - 병렬 )에 대한 설명은 FetchJoin까지 설명을 한 이후에 알아보도록 하겠습니다.
3️⃣ EntityGraphType
이는 두 가지 방식이 있습니다.
- EntityGraphType.Fetch (기본값 ) : attributePaths 또는 NamedAttributeNode에 명시한 속성들은 즉시로딩, 나머지 속성은 지연로딩.
- EntityGraphType.Load : attributePaths 또는 NamedAttributeNode에 명시한 속성들은 즉시로딩, 나머지 속성은 속성에서 정의한 로딩 전략을 따름.
아마도 기본적으로 LazyLoading으로 설정하는 것이 맞기 때문에 딱히 사용할 일은 없을 것 같네요.
✅ JPQL을 활용한 Fetch Join
@Query("SELECT p FROM Post p JOIN FETCH p.author WHERE p.id = :id")
Post findPostWithAuthor(@Param("id") Long id);Entity Graph를 사용하지 않고 JPQL을 통해서 직접 Fetch Join을 지정할 수 있습니다.
엔티티 그래프와 JPQL로 직접 Fetch Join을 하는 경우는 어떤 차이가 있을까요?
- 사용 방법: JPQL을 활용하여 Fetch Join을 하게 되면 위의 예시처럼 쿼리를 직접 작성하거나 QueryDSL과 함께할 경우에만 사용가능합니다. EntityGraph는 JPA 매서드 위에 @EnitityGraph를 선언하는 방식으로 처리합니다.
- 내부 처리 : JPQL로 작성하면 Fetch Join을 명시적으로 개발자가 작성하면 Hibernate가 이를 SQL로 변환해주고 EntityGraph는 명식적으로 개발자가 쿼리를 작성하지 않아도 연관 엔티티를 즉시 로딩하라고 힌트를 제공합니다. 사실상 큰 차이가 없다고 보시면 됩니다.
하지만, 특정 필드를 선택적으로 직접 DTO를 반환하고 싶은 경우 FetchJoin을 사용해야합니다 (Projection 사용).
⭐ 선택적 필드를 반환하는 Projection을 사용
@Query("SELECT new com.example.dto.OrderDTO(o.id, m.name, o.orderDate) " +
"FROM Order o JOIN o.member m " +
"WHERE o.orderDate >= :fromDate")
List<OrderDTO> findOrdersAfter(@Param("fromDate") LocalDate fromDate);다음과 같이 필요한 특정 필드만을 조회해서 반환하기 위해서는 무조건 JPQL을 통해서 JOIN하고 반환해야 하며 이 경우 두 가지 이점이 있습니다.
- 모든 필드를 조회하지 않기 때문에 속도가 빠름.
- DTO는 영속성 컨텍스트 대상이 아니기 때문에 영속화하는 비용이 줄어든다. (대신 그와 관련된 기능을 사용할 수 없다)
영속성 컨텍스트 관련 비용 : 메모리 소비, snapshot 생성, 비교 연산.
사용할 수 없어진 기능 : 1차 캐시에서 이미 조회했던 엔티티 가져오기 , dirty checking 등등.
따라서, 효율적이긴 하나 1차 캐시를 적극적으로 사용해야 하는 상황이라면 오히려 성능적으로 더 나빠질 수도 있다는 것을 알아야 합니다.
⚠️ Fetch Join ≠ Join
위에서 언급한 DTO 직접반환 쿼리문을 보시면 JOIN FETCH가 아닌 JOIN인 것을 확인하실 수 있습니다.
- FETCH JOIN : 연관 엔티티를 즉시 로딩하기 위해서 사용이 되며 영속성 컨텍스트로 관리됨 ( 반드시 엔티티만 가능 )
- JOIN : 조인 조건으로만 사용되며 조인 대상은 영속성 컨텍스트로 로딩되지 않습니다 (WHERE 문의 조건으로만 사용됨! )
📌 심화 개념 다루기
위에서 배운 기본 개념을 바탕으로 실전적이고 심화적인 고민을 해보고 trade-off를 비교해 보았습니다.
✅ 양방향 매핑과 단방향 매핑
저는 JPA를 처음 입문할 때 김영한님의 강의를 들었는데요 ( 많은 분들의 선생님이죠..? ㅎㅎ) 당시에 강의에서는 필요가 없다면 양방향 매핑을 굳이 사용하지 않는 편이고 양방향 매핑을 할 경우 양방향 1쪽에 컬랙션 필드를 업데이트하는 매서드를 따로 만들어 줘라 정도를 언급하신 것 같습니다.
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "member", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Order> orders = new ArrayList<>();
// ✅ 연관관계 편의 메서드
public void addOrder(Order order) {
orders.add(order); // 1. 컬렉션에 추가
order.setMember(this); // 2. 연관관계 주인 쪽도 설정
}
public void removeOrder(Order order) {
orders.remove(order); // 1. 컬렉션에서 제거
order.setMember(null); // 2. 연관관계 해제
}
}
@Entity
public class Order {
@Id @GeneratedValue
private Long id;
private String product;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "member_id")
private Member member;
public void setMember(Member member) {
this.member = member;
}
}그래서 저는 저런 것들이 번거롭다고 생각하기도 했고.
굳이 필요가 없다는 생각으로 프로젝트를 진행할 당시에도 사용하지 않았습니다. (2025.09.13일 업데이트 : cascade 삭제 시에 N+1 문제가 발생하는 것을 확인해서 사용하지 않는 것으로... 제일 큰 단점.)
실제로 예를 들어서 위의 예시에서 member의 List<Order>를 얻고 싶다면 memberId를 기준으로 List<Order>를 반환하는 매서드를 OrderRepository에 만들면 크게 불편함이 없었고.
이 경우 양방향 매핑을 사용하면 member를 얻고 .getOrder()를 통해서 얻어야 하기 때문에 오히려 member가 필요 없는 상황이라면 member를 찾는 불필요한 쿼리가 나가는 것도 방지할 수 있어서 더 좋다고 생각했어요 (물론 그거 하나 더 가져온다고 성능에 크게 문제가 되지는 않겠지만 말이죠). 그럼에도 불구하고 "좀 더 편하게 사용할 수는 있겠다" 정도로 생각하고 있었습니다.
하지만, JPA 최적화를 공부하면서 양방향 매핑 @OneToMany를 사용하게 되면 고려해야하는 부분이 그보다 훨씬 더 많아진다는 것을 깨닫게 되었고... 그 이슈에 대해서 설명해 보겠습니다.
✅ 양방향 매핑의 애매한 장점..? → 자유롭게 Fetch Join이나 Entity Graph 이용 가능

Entity Graph나 Fetch Join은 반드시 즉시로딩하는 필드가 존재해야 합니다. 위를 예시로 들자면 Order는 '다'에 속하기 때문에 연관관계의 주인으로 항상 member를 가지고 있겠죠? 그래서 List<Order>에 Order들의 Member를 즉시로딩하는 것은 항상 가능할 것입니다.
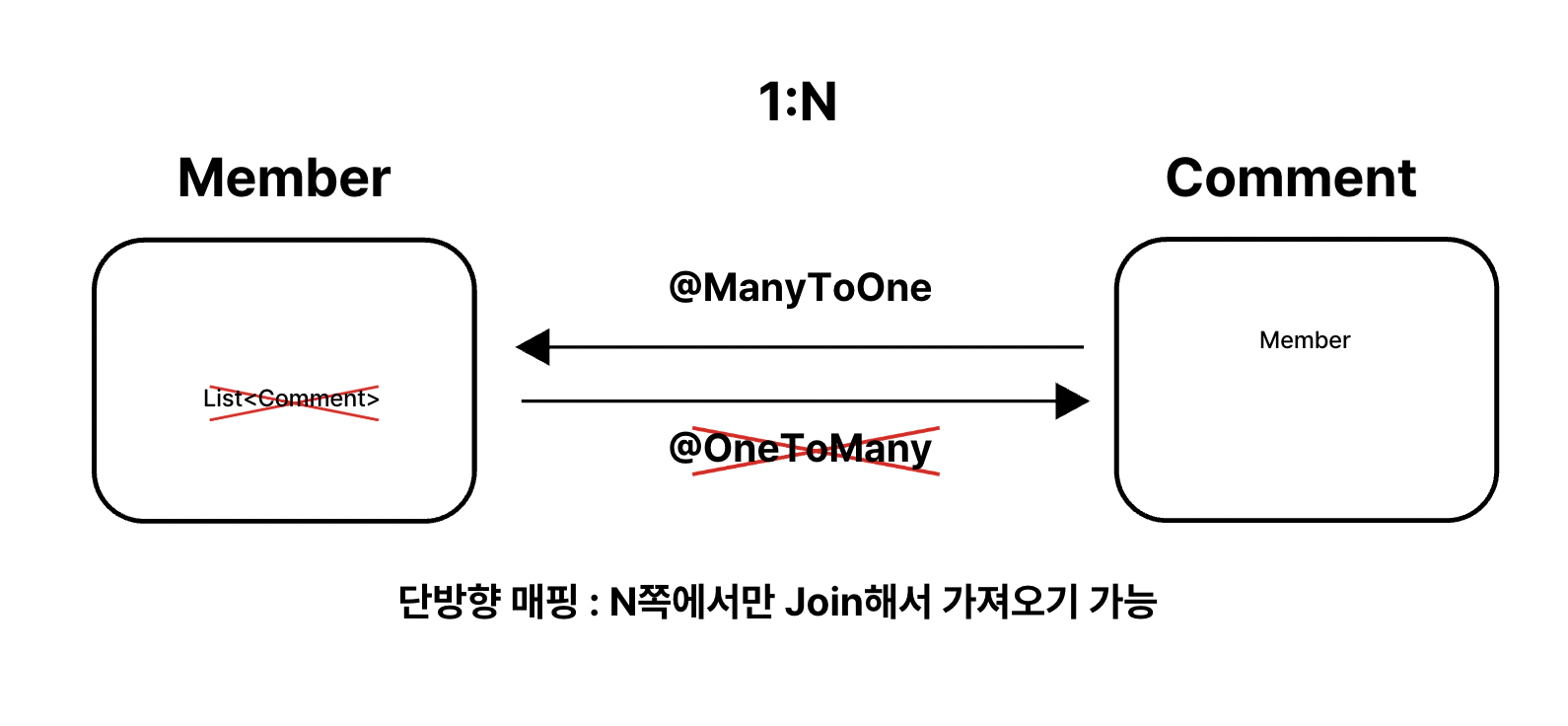
하지만, 만약 Member에서 양방향 매핑이 되어 있지 않다면 어떻게 될까요? List<Member>를 가져올 때 Comment를 즉시로딩 하는 것을 불가능합니다. 그런 필드가 없기 때문이죠.
하지만, 사실 크게 상관이 없습니다. Comment와 Member가 필요한 상황이라면 List<Comment>에 가져와서 사용하면 되기 때문이죠..? 그리고 만약 Comment들에 대한 List<Member>가 필요하다면 ( 사실 이런 상황이 크게 있을까 싶긴 합니다).
List<Comment> comments = commentRepository.findAllWithMember(); // JOIN FETCH 또는 EntityGraph 사용
List<Member> members = comments.stream()
.map(Comment::getMember)
.distinct() // 중복 제거 (옵션)
.toList();저런 식으로 가져올 수도 있습니다. 이미 Join해서 가져온 List<Comment> 이기 때문에 추가 쿼리가 나가는 N+1이 발생하지 않기 때문이죠.
이처럼 양방향 매핑을 사용하면 위와 같은 편리함이 살짝 있을 수 있습니다. 근데 이로 인해서 발생하는 고려사항(단점이라고 말하고 싶네요)에 대해서 알아보겠습니다.
✅ Paging시 발생하는 문제
Paging은 성능 최적화에서도 정말 정말 중요해서 따로 설명을 할만한 부분이지만, 양방향 매핑과 관련된 이슈가 있기 때문에 이곳에서 소개하겠습니다. 많은 양의 데이터를 불러와야 하는 경우 (ex : 게시판의 게시물 조회) 한 번에 모든 데이터를 불러오는 경우 너무 많은 양의 데이터를 불러오기 때문에 페이징을 적용하는 것은 성능에 큰 도움이 되고 또 필수적으로 적용하는 것이 좋습니다. 예를 들어서, findAll()과 같은 매서드로 하나의 엔티티의 모든 row를 가지고 오게 될 경우 굉장한 비용이 들기 때문에 이런 경우 페이징이 유용할 수 있습니다.
양방향 매핑을 적용할 경우 페이징에서 주의해야할 부분이 있습니다.
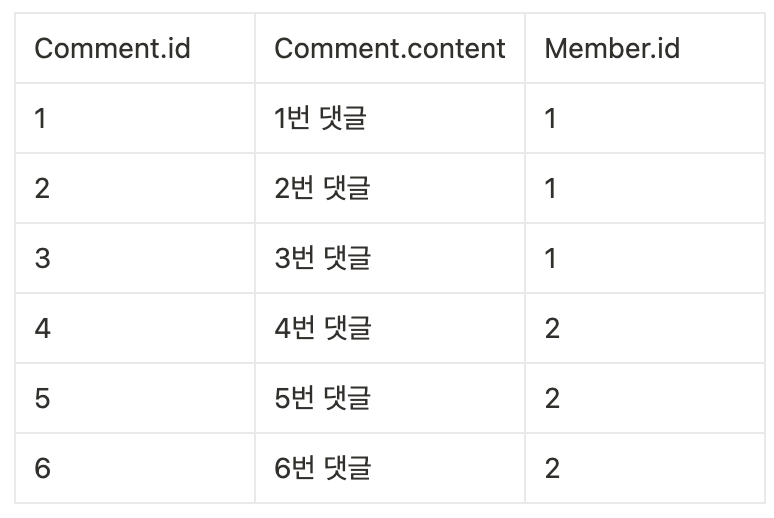
이렇게 N(다)쪽 방향에서 Join을 하면 페이징을 하는 것에 아무 문제도 없겠지만~
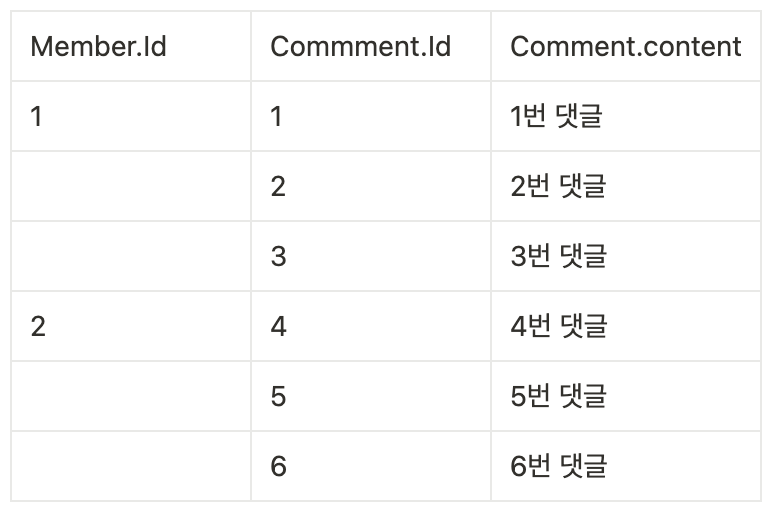
1쪽에서 하면 다음과 같이 페이징에 문제가 생기게 됩니다. root인 Member를 기준으로 페이징을 할 때 위와 같이 조인된 상태라면 중복되는 row 때문에 제대로 페이징이 작동하지 않을 수 있습니다. Member 엔티티에서 Page<Member>를 가져올 때 Comment를 Join해서 가져오면 중복되는 row 때문에 정확한 페이징이 힘들다는 이야기입니다.
Entity Graph를 사용하는 경우
이 경우 DB에서 페이징을 할 수 없습니다. 따라서 Hibernate가 상황에 맞게 내보낼 쿼리를 판단하게 됩니다. Entity Graph의 경우에는 반드시 JOIN을 강제하는 것은 아니기 때문에 다음과 같은 상황이 발생할 수 있습니다.
상황 1: 메모리로 가져와서 페이징을 수행한다.
HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!다음과 같은 메시지가 뜨면서 DB에서 페이징을 할 수 없기 때문에 Java 어플리케이션의 메모리로 가져와서 페이징을 수행합니다.
이렇게 되면 테이블을 통째로 가져오기 때문에 메모리가 낭비될 수 있으며 시간도 굉장히 오래 걸릴 수 있습니다.
상황 2: Join을 하지 않고 Select로 가져오기만 한다.
이 경우 root 엔티티만을 가져오고 컬렉션 필드가 Lazy Loading된 상태로 가져오게 됩니다. 따라서, Entity Graph를 적용해 주었음에도 불구하고 여전히 N+1 문제가 발생할 수 있습니다 (관련 내용 🔗)
상황 3: Join을 하지 않고 Select로 가져오며 IN절을 통해 Batch 실행
이 경우가 꽤나 이상적인 상황인데, 최신 버전의 Hibernate로 실행해보니 알아서 Batch 실행을 해주는 경우가 있었습니다.
근데 Hibernate에서 어떤 기준으로 선택을 하는지는 정확히 찾지 못했어요... Hibernate Q&A에서는 분명 그런 문제들이 발생할 수 있다고 쓰여있긴 합니다. 만약 이런 코드를 작성하고 계신다면 로그를 꼼꼼히 봐주어야겠죠..?
JPQL을 통해서 명시적으로 FETCH JOIN을 하는 경우
이 경우에도 위와 동일하게 DB에서 페이징이 불가능합니다. 하지만, Join을 강제하기 때문에 Entity Graph와 살짝 상이합니다.
상황 1: 메모리로 가져와 페이징을 수행
상황 2: 버전에 따라서 에러가 발생할 수 있음
org.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bags다음과 같은 에러 발생
이런 경우, 여전히 양방향 매핑을 사용하고 싶다면 다음과 같은 해결책이 있어요.
대안 1: root 엔티티의 id 값을 먼저 가져오고 컬렉션을 로딩해라 ( JPA 팀의 Vlad Mihalcea가 추천한 방법 🔗)
root 엔티티 (1:N에서 1)의 id값을 먼저 로딩(list든 page든) 가져오고 나머지 컬렉션을 로딩하면 됩니다.
// 첫 번째 쿼리: ID 목록 조회
List<Long> ids = entityManager.createQuery(
"SELECT m.id FROM Member m ORDER BY m.name", Long.class)
.setFirstResult(0)
.setMaxResults(10)
.getResultList();
// 두 번째 쿼리: 연관된 컬렉션 로딩
List<Member> members = entityManager.createQuery(
"SELECT m FROM Member m LEFT JOIN FETCH m.cars WHERE m.id IN :ids", Member.class)
.setParameter("ids", ids)
.getResultList();(이렇게까지 해서 양방향 매핑으로 페이징을 사용할 이유가...?)
대안2: 이런 경우 Batch를 유용하게 사용할 수 있습니다.
Page<Member> findAll(Pageable pageable);레포지토리에서 꺼내올 때는 그냥 컬렉션 필드를 즉시로딩하지 않은 상태로 가져오고
@BatchSize(size =5)
@OneToMany(mappedBy = "member", fetch = FetchType.LAZY)
private List<Car> cars = new ArrayList<>();컬렉션 필드에 BatchSize를 걸어주는 방법입니다.
✅ MultipleBagFetchException 발생 가능
@Entity
...
public class Parent {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "P_ID", nullable = false)
private long id;
// 양방향
@OneToMany(mappedBy = "parent", fetch = FetchType.LAZY, cascade = CascadeType.ALL)
private List<Child> childEntity = new ArrayList<>();
// 양방향
@OneToMany(mappedBy = "parent", fetch = FetchType.LAZY, cascade = CascadeType.ALL)
private List<Child> dogEntity = new ArrayList<>();
}@Repository
public interface ParentRepository extends JpaRepository<Parent, Long> {
@EntityGraph(attributePaths = {"childEntity", "dogEntity"})
List<Parent> findAll();
}다음과 같이 2개 이상의 toMany를 Fetch 해서 가져오는 경우 MultipleBagFetchException이 터질 수 있습니다. 이런 구조를 병렬적 트리라고 합니다.
(직렬적 트리구조 예시)
Parent
└── List<Child>
└── List<Toy>(병렬적 트리구조 예시)
Parent
├── List<Child>
└── List<Dog>양방향 매핑을 사용할 경우 모두 고려해 주시면 된다.
📌 기타 최적화 방법
✅ DISTINCT 사용
@Query("""
SELECT DISTINCT p
FROM Parent p
JOIN FETCH p.children
""")
List<Parent> findAllWithChildren();@OnToMany 즉 양방향 매핑을 사용할 경우 JPQL의 DISTINCT를 사용하면 Hibernate에게 "root entity 기준으로 중복 제거해라" 라는 신호를 주게 됩니다. 이렇게 하면 SQL에서는 중복 row가 있을 수 있지만 Hibernate에서는 한 개의 root 객체만 생성합니다.
✅ FetchMode.SUBSELECT
@OneToMany(mappedBy = "member", fetch = FetchType.LAZY)
@Fetch(FetchMode.SUBSELECT)
private List<Order> orders;IN 절을 통해서 컬랙션을 한 번에 가져오게 됩니다. (N+1 문제 해결 가능)
✅ Index 부여하기
인덱스를 부여하게 되면 조회 속도가 크게 향상되는 대신 DB에 추가적인 저장 공간이 필요하고 쓰기와 수정하는 성능은 저하된다는 단점이 있다. 하지만, 테이블이 커지고 데이터가 많아질수록 다른 부분들보다 중요한 최적화 대상입니다.
✅ OSIV(Open Session In View)
spring:
jpa:
open-in-view: true # ✅ 기본값기본적으로 OSIV 설정은 켜져 있습니다.
@GetMapping("/members")
public String members(Model model) {
List<Member> members = memberService.findAll(); // Lazy 관계들 포함
model.addAttribute("members", members); // View에서 members.getOrders() 같은 접근
return "members/list";
}이는 다음과 같은 트랜잭션 바깥의 상황에서도 Session이 열려있어서 Lazy 로딩이 가능하게 만들어주는 기능입니다. 저 같은 경우에는 프로젝트에서 DTO를 사용해주고 있고 트랜잭션 외부에서 세션을 사용할 일이 없기 때문에 꺼주는 것이 효율적일 것이라고 생각했습니다.
@GetMapping("/{historyId}")
@Operation(summary = "특정 유저의 특정 일의 기록을 확인할 수 있는 API")
@ApiResponses({
@io.swagger.v3.oas.annotations.responses.ApiResponse(responseCode = "HISTORY_200", description = "OK, 성공적으로 조회되었습니다."),
})
@Parameters({
@Parameter(name = "historyId", description = "기록의 id, path variable 입니다.")
})
public BaseResponse<HistoryResponseDTO.DailyHistoryResult> getDailyHistory(@PathVariable @Valid Long historyId,
@Parameter(name = "user", hidden = true) @AuthUser Member member) {
HistoryResponseDTO.DailyHistoryResult result = historyService.getDaily(historyId, member.getId());
return BaseResponse.onSuccess(SuccessStatus.HISTORY_SUCCESS, result);
}이런 식으로 DTO를 받는다면..? 커넥션 풀도 효율적으로 사용할 수 있도록 OSIV를 꺼주는 것이 좋아 보입니다.
📌 나의 최적화 CheckList
- 양방향 매핑을 사용하지 않는다
- N+1 문제를 꼼꼼히 점검한다. (EntityGraph 또는 JPQL을 통한 Fetch Join)
- 필요한 필드만 DTO 직접 반환(Projection)을 효율적으로 사용할 수 있는 경우 사용한다
- 많은 데이터를 불러오는 경우 페이징을 사용하자
- 적재적소에 인덱스를 적용한다
- DTO를 사용하고 있다면 OSIV를 꺼주자
'프로젝트' 카테고리의 다른 글
| 양방향 매핑을 왜 함부로 사용하면 안될까? 삭제 성능 최적화 (0) | 2025.09.23 |
|---|---|
| 테스트 코드는 어떻게 작성해야 할까? - 좋은 테스트 코드 작성 TMI (1) | 2025.07.01 |
| 배포의 모든 것 - 5. Blue-Green 무중단 배포 적용 (2) | 2025.05.01 |
| Clokey 프로젝트 리펙토링 - Github Actions & Docker 최적화 (0) | 2025.04.29 |
| Docker에 대해서 알아보자 - 3. docker build & docker compose (0) | 2025.04.26 |